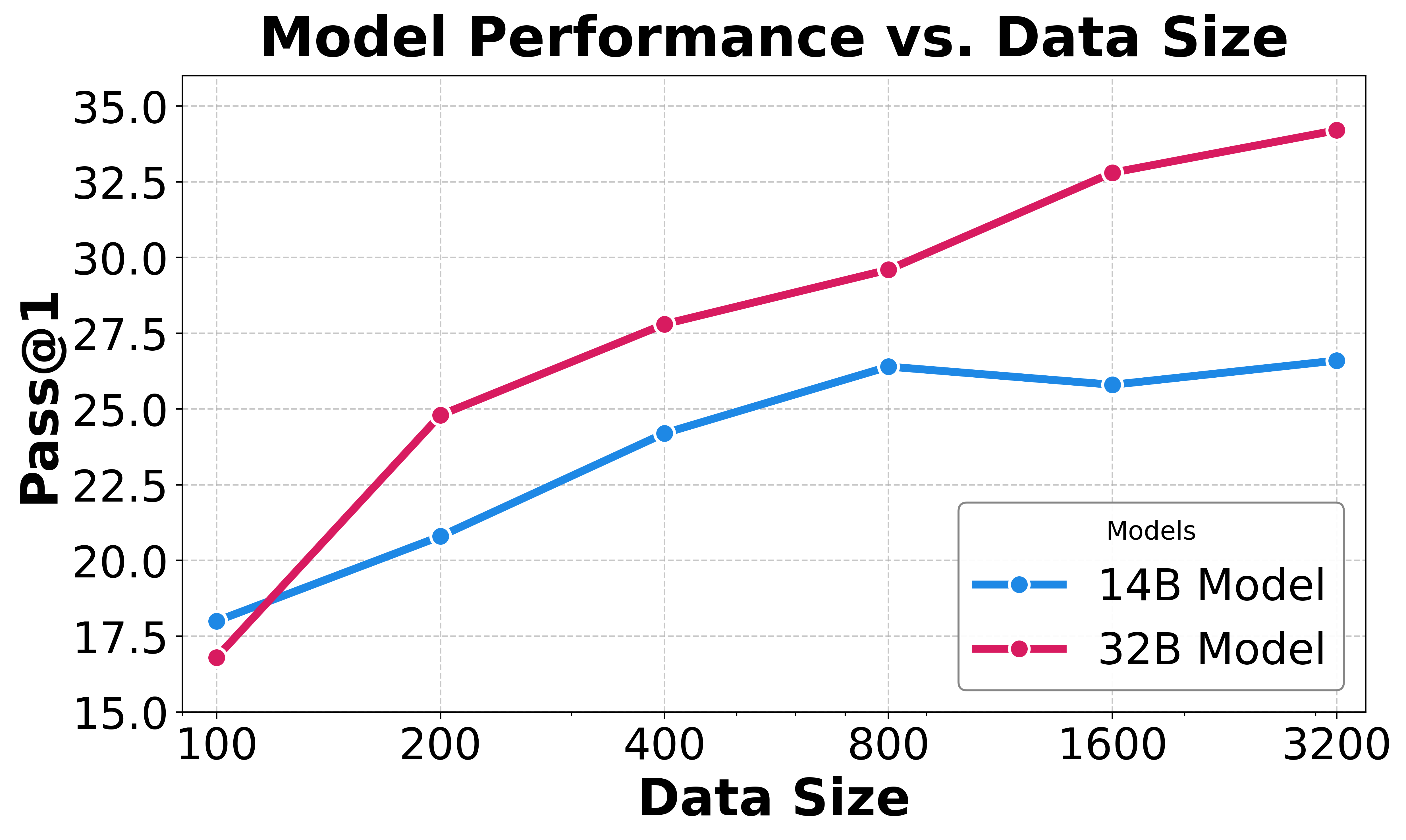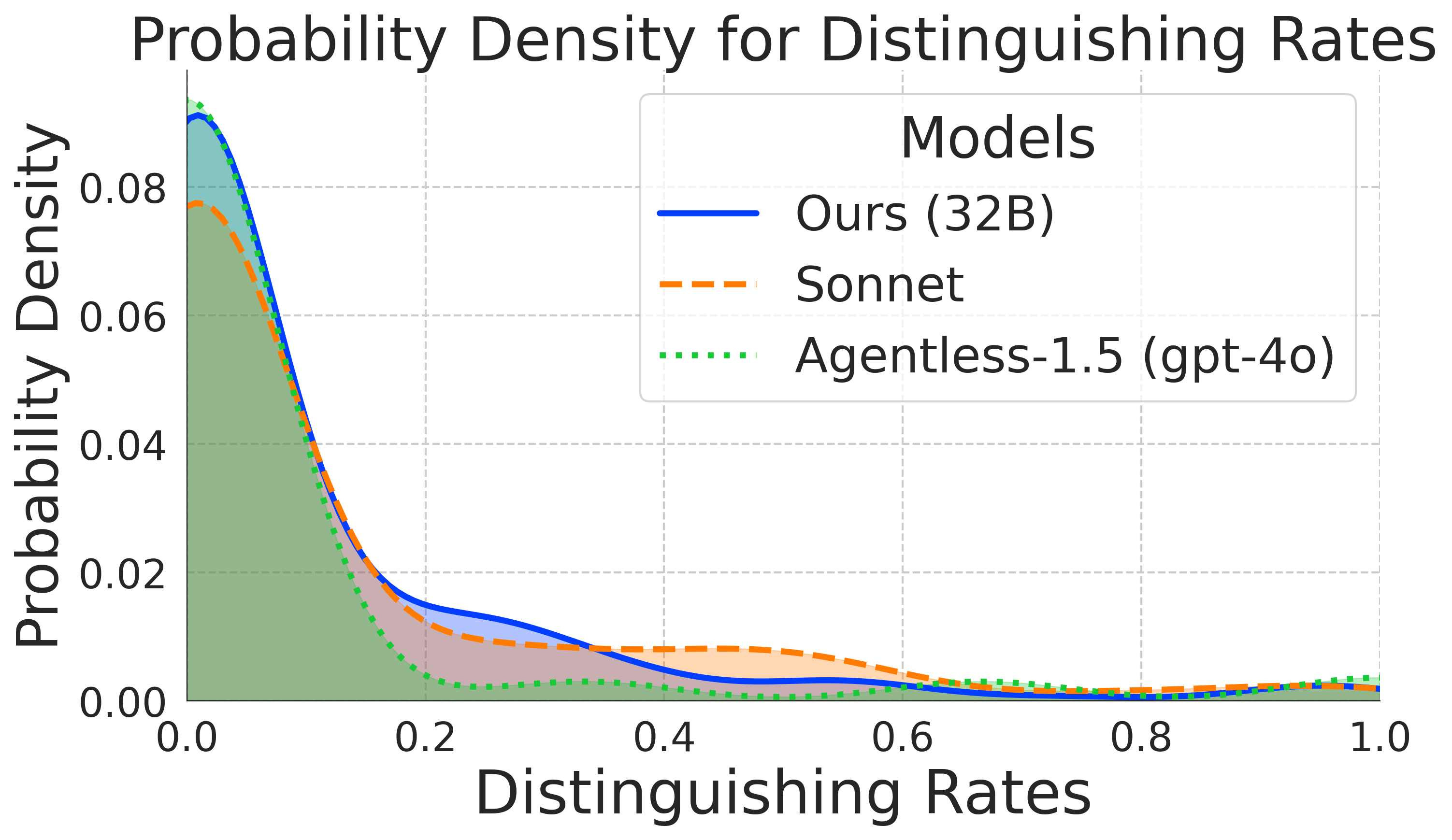
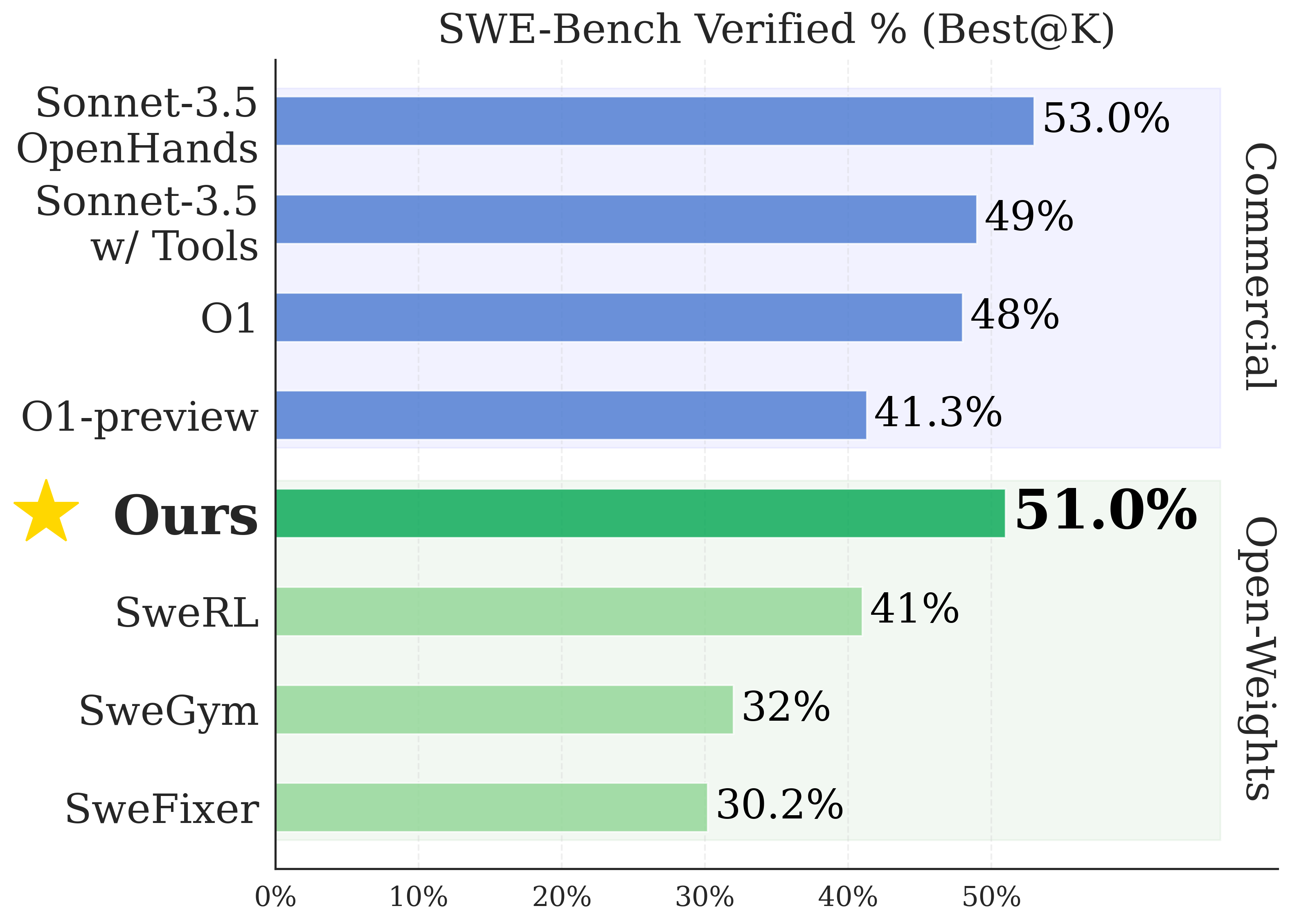
Autonomous software engineering (SWE) has made remarkable progress in solving real-world programming challenges. While LLM-based SWE agents have demonstrated impressive capabilities, current state-of-the-art performance is predominantly achieved by proprietary models, with open-source alternatives lagging significantly behind. Closing this performance gap requires addressing two core challenges: First, we need scalable methods to curate diverse, high-quality execution environments for training. Second, we need efficient strategies for scaling test-time compute.
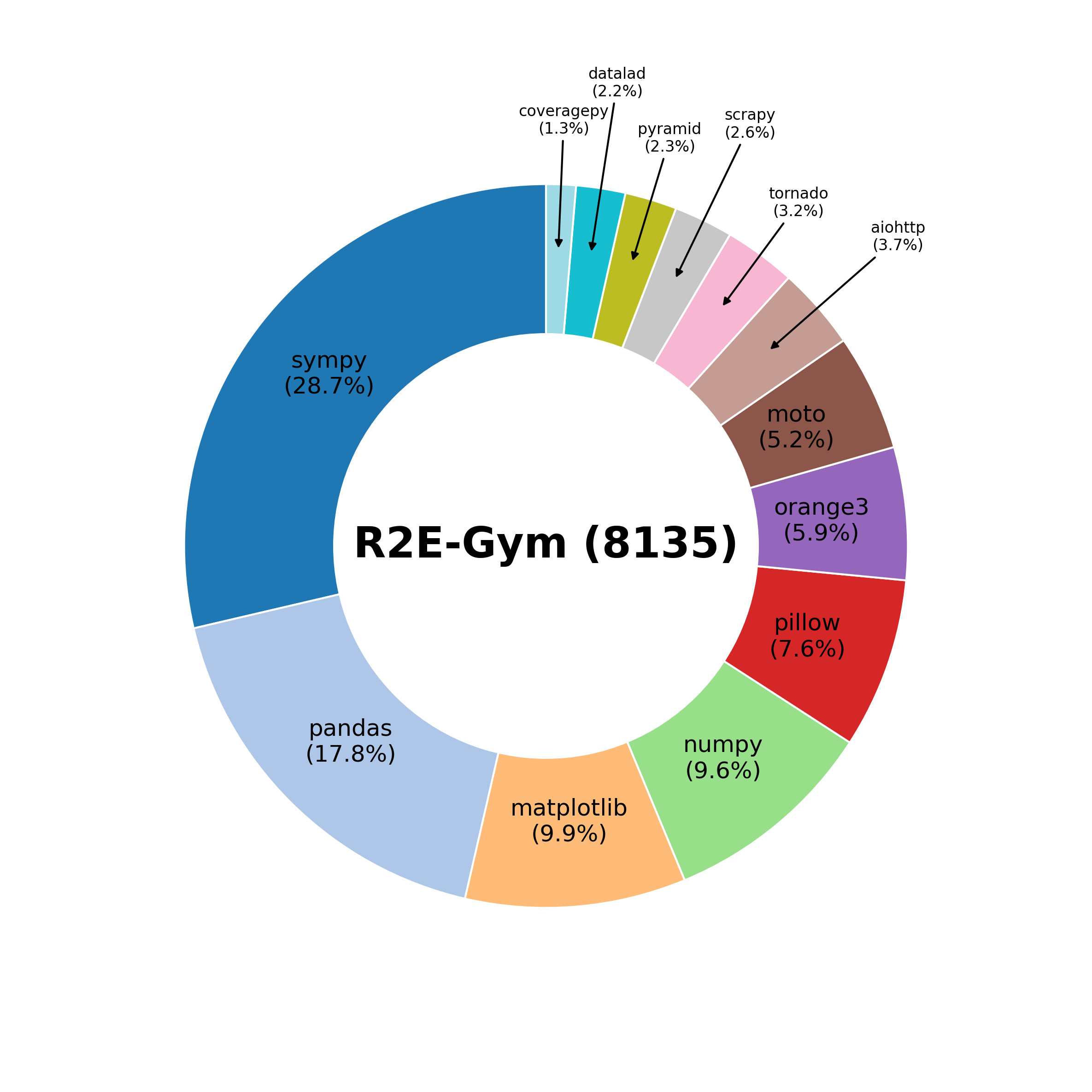
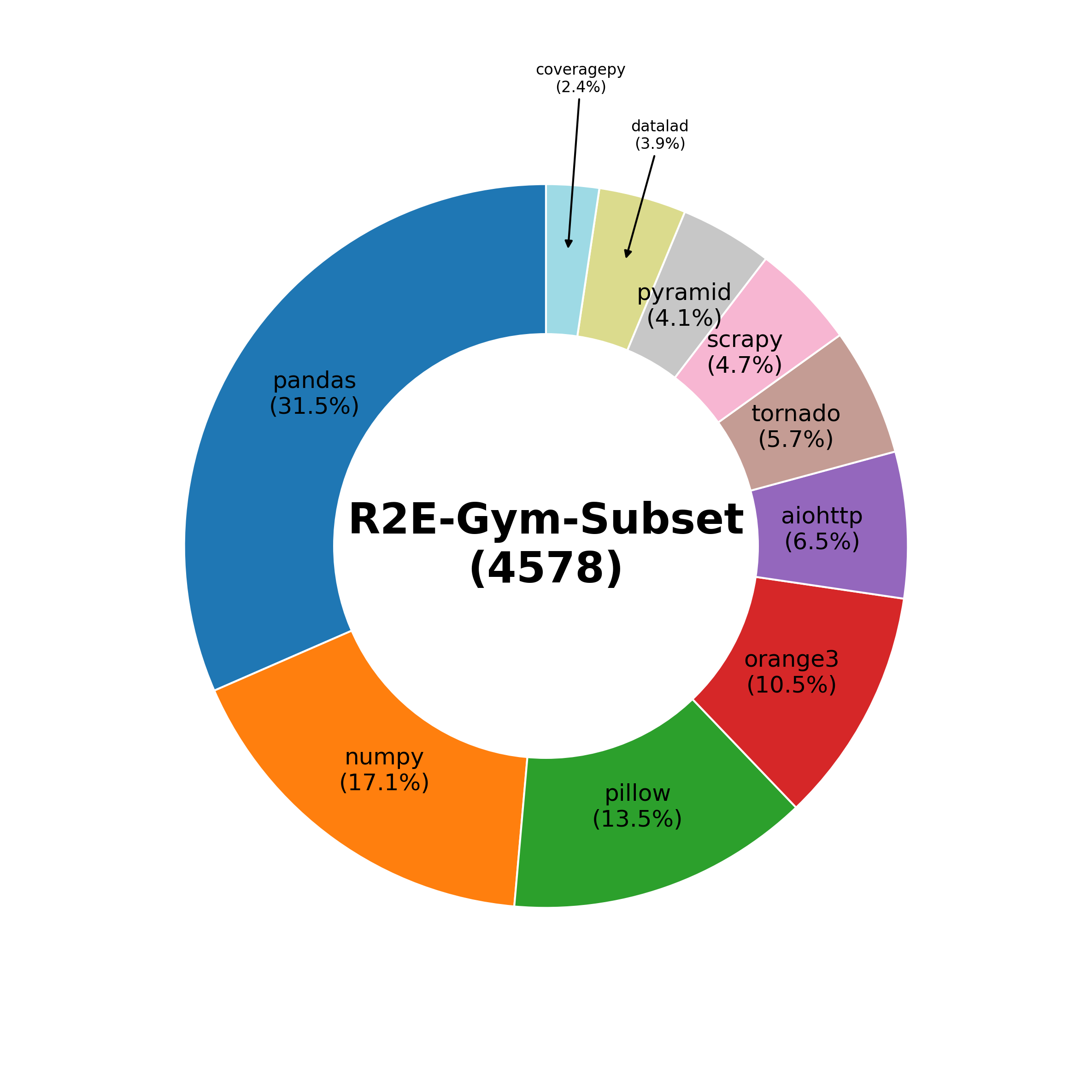
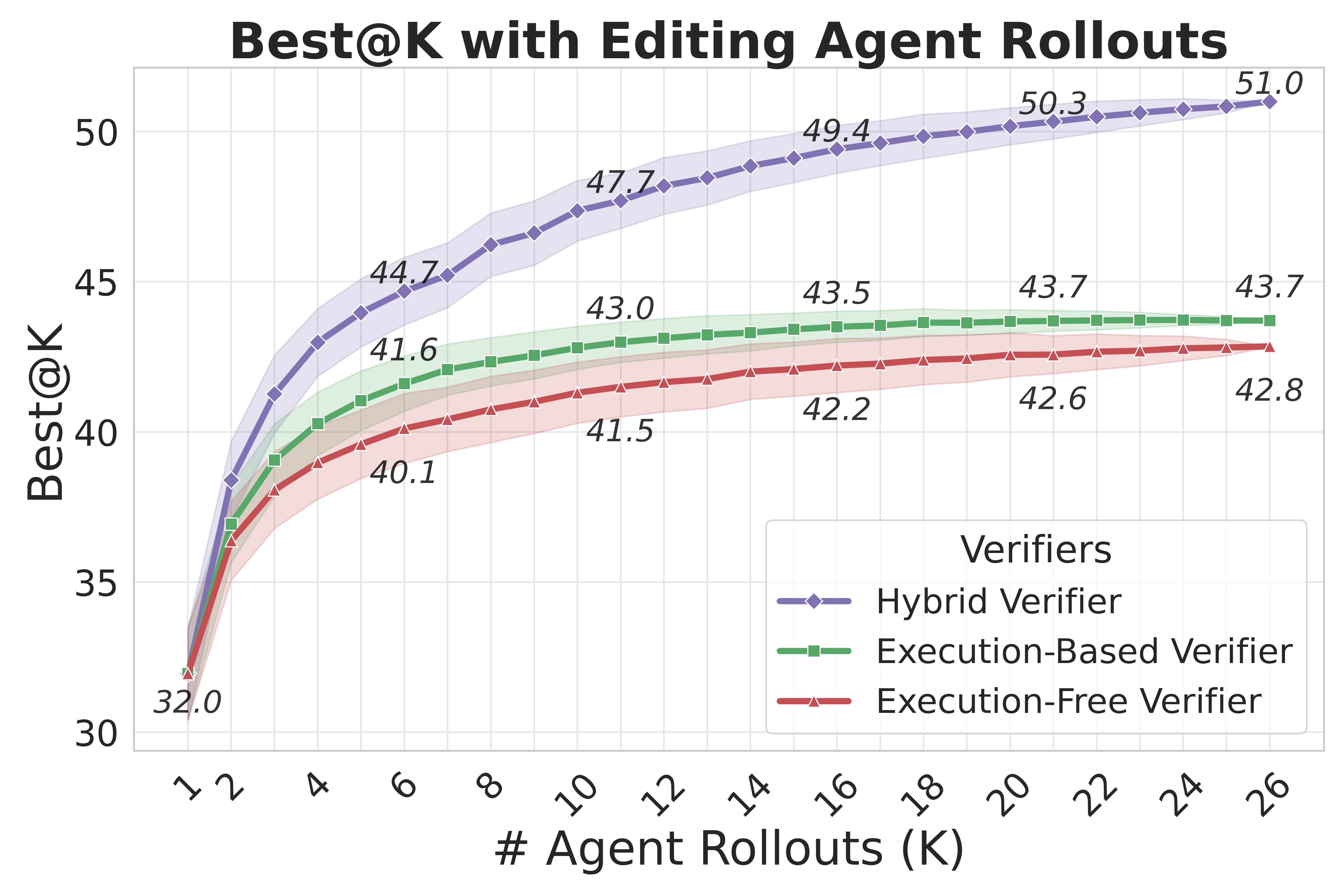
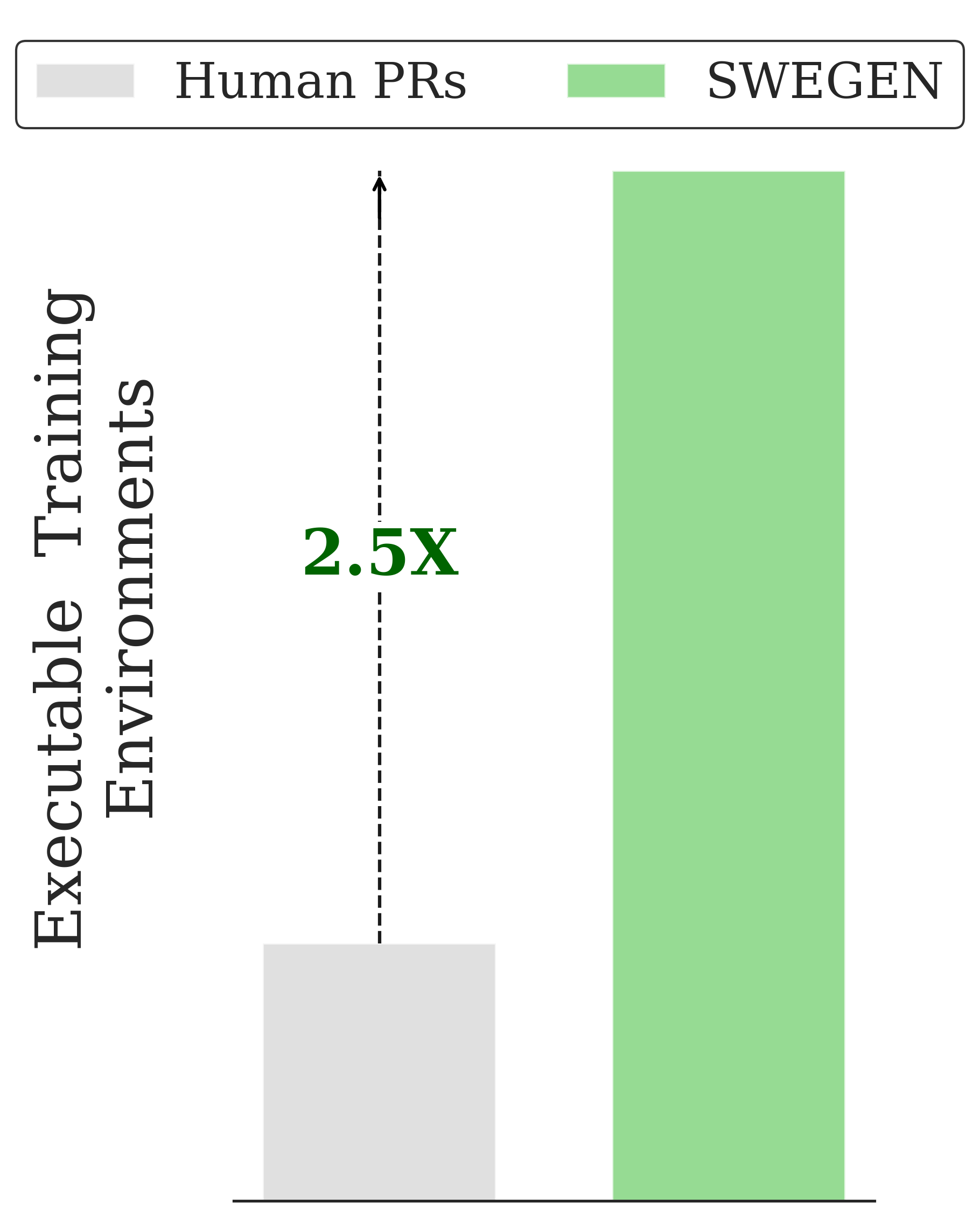
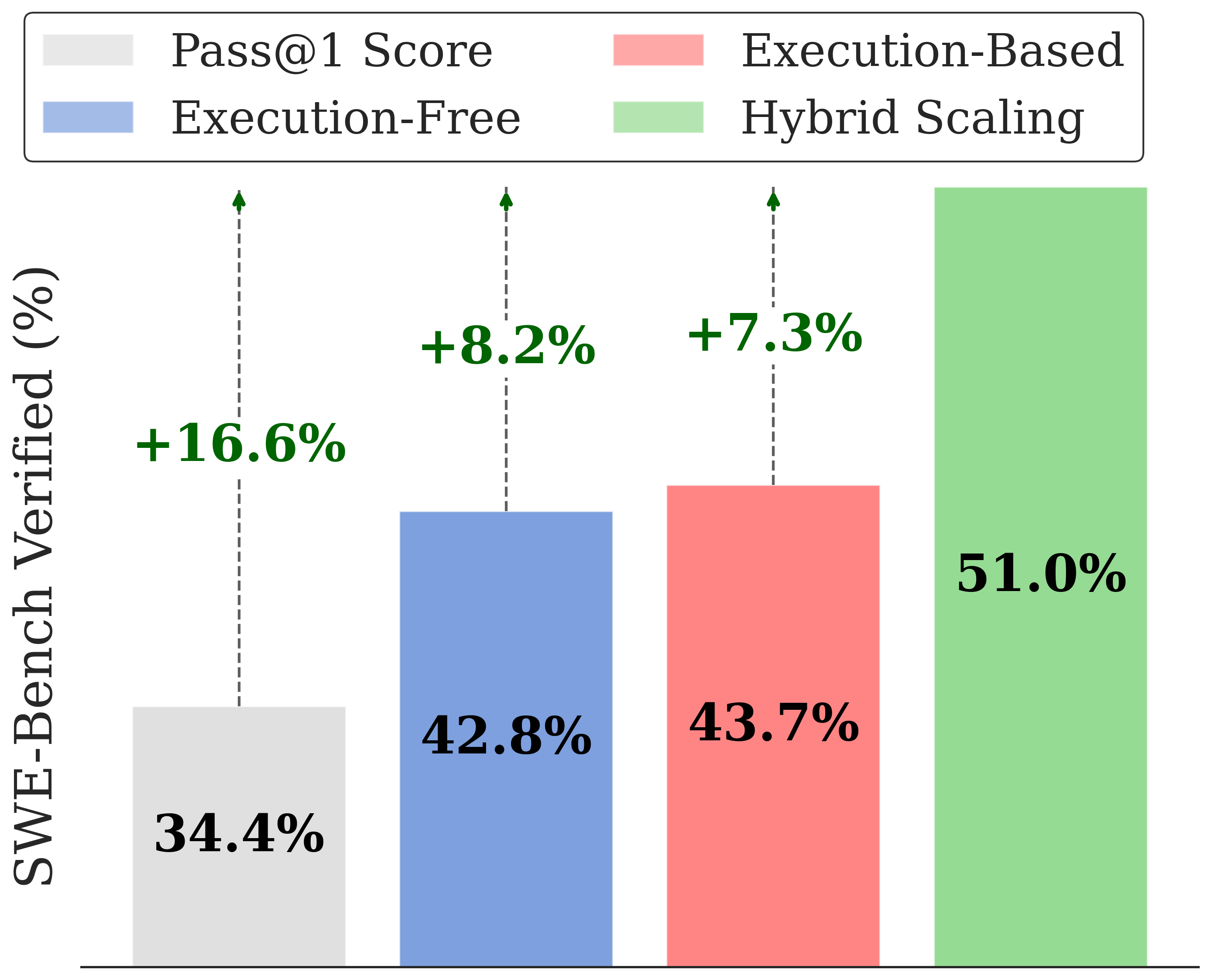
R2E-Gym addresses these challenges as the largest procedurally generated environment for training real-world SWE agents—comprising over 8.1K problems with executable environments and problem statements through our SWE-Gen pipeline. Next, we introduce a hybrid verifiers that combines the strengths of execution-based and execution-free verification methods, enabling significantly better performance at test time.